给我1张图,生成30秒视频!|DeepMind新作
扫一扫
分享文章到微信

扫一扫
关注99科技网微信公众号
磐创AI分享
转自 | 新智元编辑 | Joey 桃子
【导读】 近日,DeepMind提出了一种基于概率帧预测的图像建模和视觉任务的通用框架——Transframer。AI又进阶了? 而且是一张图生成连贯30秒视频的那种。 emm....这质量是不是有点太糊了 要知道这只是从单个图像(第一帧)生成的,而且没有任何显示的几何信息。 这是DeepMind最近提出的一种基于概率帧预测的图像建模和视觉任务的通用框架——Transframer。 简单讲,就是用Transframer来预测任意帧的概率。 这些帧可以以一个或者多个带标注的上下文帧为条件,既可以是先前的视频帧、时间标记或者摄像机标记的视图场景。
Transframer架构
先来看看这个神奇的Transframer的架构是怎么运作的。论文地址就贴在下面了,感兴趣的童鞋可以看看~ https://arxiv.org/abs/2203.09494 为了估计目标图像上的预测分布,我们需要一个能够生产多样化、高质量输出的表达生成模型。 尽管DC Transformer在单个图像域上的结果可以满足需求,但并非以我们需要的多图像文本集 {(In,an)}n 为条件。 因此,我们对DC Transformer进行了扩展,以启用图像和注释条件预测。 我们替换了DC Transformer 的Vision-Transformer风格的编码器,该编码器使用多帧 U-Net 架构对单个DCT图像进行操作,用于处理一组带注释的帧以及部分隐藏的目标DCT图像。 下面看看Transframer架构是如何工作的。
(a)Transframer将DCT图像(a1和a2)以及部分隐藏的目标DCT图像(aT)和附加注释作为输入,由多帧U-Net编码器处理。
接下来,U-Net输出通过交叉注意力传递给DC-Transformer解码器,该解码器则自动回归生成与目标图像的隐藏部分对应的DCT Token序列(绿色字母)。
99科技网:http://www.99it.com.cn





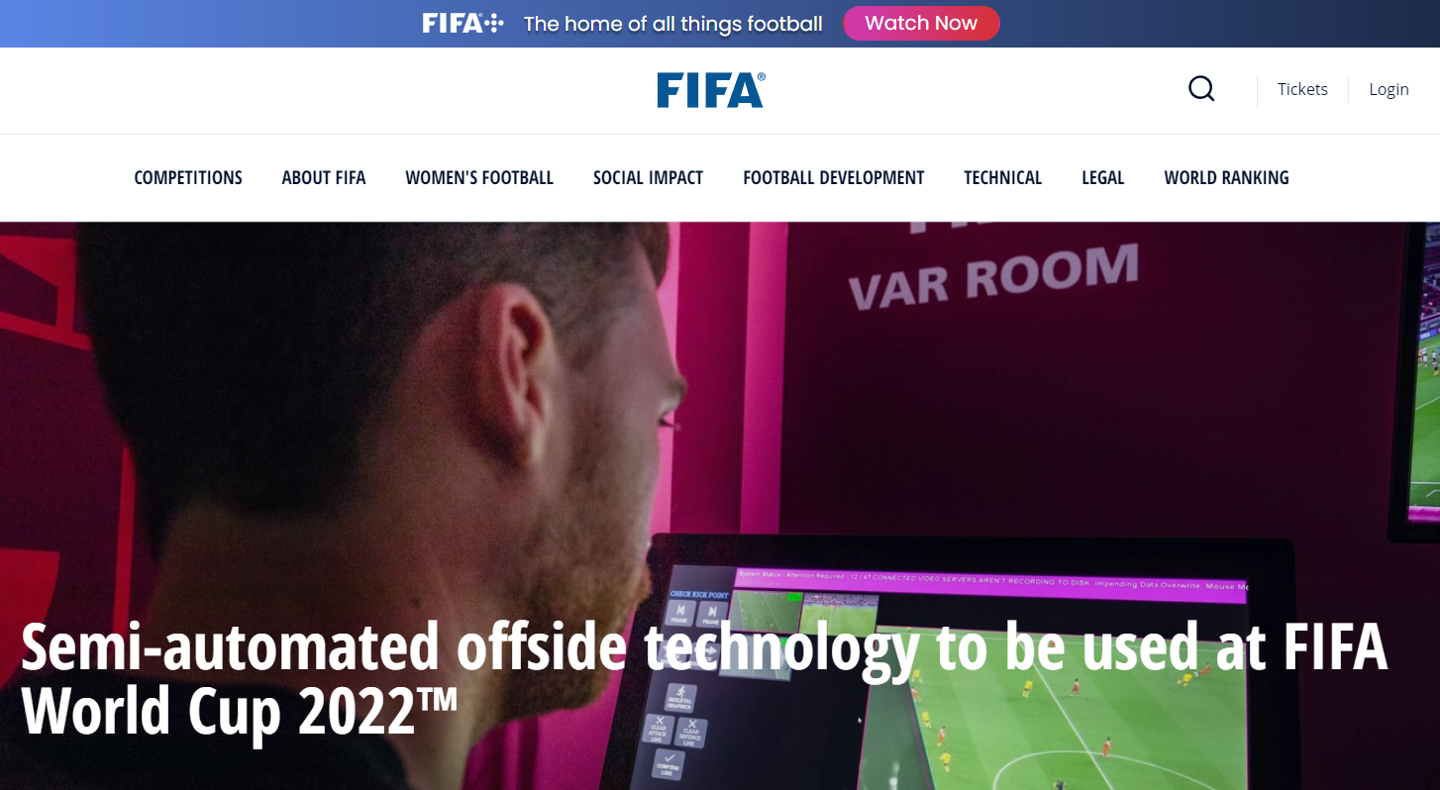 2022 卡塔尔世界杯用上新的“黑科技”:足球内嵌传感器,12 个摄像头追踪越位,还能生成 3D 动画
2022 卡塔尔世界杯用上新的“黑科技”:足球内嵌传感器,12 个摄像头追踪越位,还能生成 3D 动画
IT之家 7 月 2 日消息,国际足联今日发文称,2022 年卡塔尔世界杯将采用新的 半
快资讯2022-07-02









 推荐资讯
推荐资讯






