首次在智能手机上训练BERT和ResNet,能耗降35%(2)
扫一扫
分享文章到微信

扫一扫
关注99科技网微信公众号
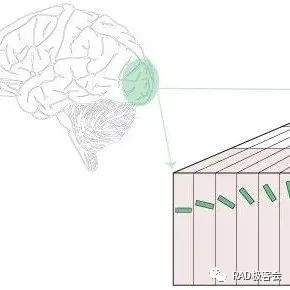
图注:POET 在边缘设备上对 SOTA 机器学习模型的训练进行优化。
对于部署在真实世界边缘设备上的模型,当边缘设备出现空闲并可以计算周期时就会进行训练,例如谷歌 Gboard 会在手机充电时安排模型更新。因此,POET 也包含了严格的训练限制。给定内存限制和训练 epoch 的数量,POET 生成的解决方案也能满足给定的训练截止期限。此外,研究者还利用 POET 开发了一个全面的成本模型,并证明它在数学上是保值的(即不做近似),适用于现有的开箱即用架构。
论文一作 Shishir Patil 在演示视频中表示,POET 算法可以在智能手机等商用边缘设备上训练任何需要极大内存的 SOTA 模型。 他们也成为了首个展示在智能手机和 ARM Cortex-M 设备上训练 BERT 和 ResNet 等 SOTA 机器学习模型的研究团队。
集成分页和重新实现
重新实现和分页是降低大型 SOTA ML 模型内存消耗的两种技术。在重新实现中,一旦不再需要激活张量就会被删除,最常见的是在前向传播期间。从而释放了宝贵的内存,可用于存储后续层的激活。当再次需要删除的张量时,该方法会根据谱系的规定从其他相关的激活中重新计算。而分页,也称为 offloading,是一种减少内存的补充技术。在分页中,不是立即需要的激活张量从主存储器调出到二级存储器,例如闪存或 SD 卡。当再次需要张量时,将其分页。
图 2 显示了一个八层神经网络的执行时间表。沿着 X 轴,每个单元对应神经网络的每一层(共 8 层 L8)。Y 轴表示一个 epoch 内的逻辑时间步长。图中占用的单元(用颜色填充)表示在相应的时间步执行的操作(前向 / 后向传播计算、重新实现或分页)。
例如,我们可以看到 L1 的激活是在第一个时间步 (T1) 计算的。在 T2 和 T3 时刻,分别计算 L2 和 L3 的激活量。假设层 L2 和 L3 恰好是内存密集型但计算成本较低的运算,例如非线性 (tanH、ReLU 等),那么重新实现就成为了最佳选择。我们可以删除激活({T3, L2}, {T4, L3}) 来释放内存,当后向传播过程中需要这些激活时,可以再重新实现它们({T14, L3}, {T16, L2})。
99科技网:http://www.99it.com.cn














 推荐资讯
推荐资讯






