谷歌复用30年前经典算法,CV引入强化学习,网友:视觉RLHF要来了?(2)
扫一扫
分享文章到微信

扫一扫
关注99科技网微信公众号
奖励
在不丧失泛化性的情况下,该研究将 CV 任务描述为学习一个函数的过程,该函数将输入 x(即图像)映射到输出 y = [y_1, y_1,……, y_n](文本 token 序列、bounding box 序列等)。该研究旨在学习以 θ 为参数的条件分布 P (y|x, θ),使奖励函数 R 最大化。用抽象的公式来形容,就是本文要解决以下优化问题。 问题有了,接下来就是怎么解决了,本文分两步走:首先用最大似然估计对模型进行预训练;然后使用 REINFORCE 算法对模型进行 Tuning 。下面我们看看这两步的具体过程: 最大似然预训练 首先使用最大似然原理估计参数 θ 并捕获训练数据的分布。实现这一目标可采用梯度下降算法,该算法通过最大化训练数据的 log-likelihood 来实现。算法 1 和图 2 描述了 MLE(最大似然估计)优化步骤,这是训练模型最常用的方法。完成这一步将得到 MLE 模型。 REINFORC 算法将奖励最大化 为了更好的优化 MLE 模型以适应任务风险,还需要最大化奖励函数。对于给定输入 x,该研究利用 REINFORCE 算法来估计对给定 x 期望奖励的梯度,公式如下所述: 算法 2 提供了伪代码,图 3 说明了该过程:
实验结果
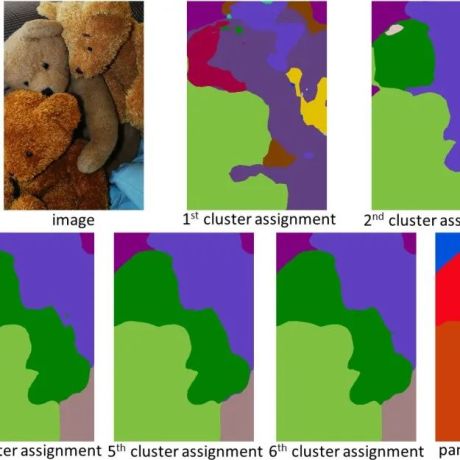
接下来我们看看本文提出的方法在视觉任务上的表现。 全景分割 如下表 1 所示,Tuning 过程显著改善了 MLE 模型。视觉检查(visual inspection)后的结果表明,Tuning 后的模型在避免不连贯预测方面更好,特别是对于小尺度物体,可参见图 1。 目标检测 表 2 显示,通过优化,该研究将原始 MLE 模型的 mAP 分数从 39.2% 大幅提高到 54.3%。在 Pix2seq 中,具有稍大的 1333×1333 分辨率和许多启发式的相同大小的 ViT-B 模型达到了 47.1%。当使用更大的 ViT-L 主干时,Pix2seq 报告的最佳目标检测结果为 50.0%。 上色 图 4 给出的定性结果清楚地表明,新模型始终能产生更丰富多彩的图像。 图像描述 表 3 结果表明,应用所提出的方法可以改进 MLE 模型,这与先前文献中的观察结果一致,证明了该方法针对特定任务风险进行 tuning 的有效性。
99科技网:http://www.99it.com.cn














 推荐资讯
推荐资讯






